Eindverantwoording
Michiel Vlieger - Unrest Predictor
Michiel Vlieger - Unrest Predictor

Het eindproduct wordt een webapplicatie dashboard. Via een overzicht kan je alle bedrijven zien en of het onrustig is. Deze onrust wordt voornamelijk door middel van ...
Natuurlijk loopt het nooit exact als de planning, in mijn geval liep het erg soepel tot en met fase 6. Daarna bij fase 7 liep het erg uit...
Voor dit project had ik een aantal doelen. Deze doelen zijn te verdelen in project doelen en persoonlijke doelen. Mijn project doelen gaan voornamelijk over het eindproduct en de kwaliteit ervan...
Voor dit project heb ik een aantal doelen. Deze doelen zijn te verdelen in project doelen en persoonlijke doelen. Mijn project doelen gaan voornamelijk over het eindproduct en de kwaliteit ervan...
Mijn volledige naam is Joram Michiel Vlieger, maar Michiel is mijn
roepnaam... Maar wat
is er veranderd? Ik ben volgens mijn gevoel veel gegroeid. Van wat willekeurige kennis
van Machine Learning Networks(MLN) ben ik naar het praktisch toepassen van MLN's gegaan.
Later bij de doelen kan je er meer over lezen. Ik heb namelijk gehoord dat ik meer
over mijzelf moet delen dus dat ga ik met dit verslag proberen doen. Ik
heb deze minor belangrijke dingen over mijzelf geleerd.
Ten eerste heb ik een goede werkmethode gevonden voor mijzelf. Ik heb de ontbrekende
factor van mijn zelfmanagement ontdekt. Hierover meer te vinden in 'Hoe ga ik te
werk?'.
Daarnaast heb ik vanwege de covid-19 lockdown gemerkt hoe belangrijk ik fysiek contact
vind. Ik dacht namelijk dat ik fysiek contact niet echt nodig had. Maar na een week
binnen zitten merkte ik hoe erg ik het nodig had om af en toe een rondje te lopen met
een vriend.
Bovendien zit ik als programmeur vaak toch te veel stil achter mijn computer. Ik had
opgemerkt dat ik na te lang stilzitten last kreeg van mijn rug. Daarom heb ik ervoor
gekozen om elk uur een keer te stretchen/ mijn benen te strekken.
Op dit moment manage ik mijn projecten met een aantal methodes, waarvan ik weet dat ze
goed werken voor mij (een ding was was wel veranderd - geel gedrukt).
Een van deze methodes is mijzelf belonen wanneer ik iets behaal. Ook bij dit project
ga ik deze vorm van management gebruiken. Ik ga namelijk betaald worden wanneer ik dit
product verkoop aan de opdracht gever. Als beloning wil ik op vakantie gaan met een
gedeelte van het geld. Daarnaast ga ik mijzelf belonen door voldoende pauzes te geven om
tot rust te komen. Dit zorgt ervoor dat ik niet overspannen raak en fris door kan werken
met een prettig gevoel.
Een andere methode om mijzelf te sturen is dingen doen die ik leuk vind om te doen. Als
ik ergens geen zin in heb, met betrekking tot het project, kan ik misschien aan een
andere taak werken tot ik zin krijg om het weer op te pakken.
Nog een andere methode voor zelfmanagement voor mij is deadlines zetten. Ik gebruik
dit project scrum. Scrum zorgt ervoor dat ik van tevoren moet aan
geven wat ik in een sprint af wil hebben en na de sprints kan ik zien hoe snel ik werkte
waardoor ik volgende sprints beter kan inplannen. Deze sprints zijn dus deadlines die ik
voor mijzelf zet.
Alleen maak ik ze nu niet meer alleen voor mijzelf, maar ik laat Daniël elke week
kijken naar mijn progressie. Dit forceert mij om mijzelf niet te veel te matsen.
Waar ik door de covid-19 lockdown af en toe moeite mee had. Dit werkt veel beter
voor mij aangezien er anders niemand meekijkt of ik wel mijn werk doe, wat mij het
idee geeft dat ik meer pauzes kan nemen dan zou horen.
Natuurlijk loopt het nooit exact als de planning, in mijn geval liep het erg soepel tot
en met fase 6. Daarna bij fase 7 liep het erg uit. Ik had 2 weken ingeschat voor het
maken van de dataset, wat uiteindelijk dus 4 weken werd. Niet het einde van de wereld!
Ook al leek dat wel te gebeuren dit jaar.
Fase 8 ging juist weer sneller voorbij dan ik
had verwacht. Dat kwam omdat ik op het zelfde moment mijn vriendin aan het helpen was
met haar master, waar dit onderwerp uitgebreid uitgelegd en geofend werd. Ik heb veel
geleerd van de Datamining course waar ze meebezig was. Namelijk over andere soorten
predictie modellen dan MLN zoals: de random decision forest model, logistic regression
model en decision tree model. Door het onderzoek naar verschillende predictie modellen
heb ik meer geleerd over hoe MLNs werken. Maar het belangrijkste wat ik van die cursus
had geleerd was het behandelen van data. Ik had hier nog niet veel kennis van omdat de
vorige MLN, die ik voor de status update had gemaakt, al een bestaande en schoongemaakte
dataset had. Bij de cursus was er een opdracht om spam berichten uit gewilde berichten
te halen door middel van een predictie model. Deze opdracht had ik met mijn vriendin
gemaakt waardoor ik veel leerde over het schoonmaken van tekstdata voor het analyseren
met een predictie model.
Bij de status update had ik verwacht dat ik in ieder geval bij stap 10 zou zijn om deze
tijd. Jammer genoeg is dat niet gelukt. Uiteindelijk had ik een week voor het inleveren
van de eindverantwoording de eerste versie af. Daarvoor had ik al wel een product dat
iets kon verspellen maar ik wou een hogere nauwkeurigheidsgraad (boven 85% goed). Het
uiteindelijk product raad ~90.2% van de tijd goed waar ik heel tevreden mee ben.
Natuurlijk ga ik hem later verbeteren om richting de 99% te gaan, maar voor nu ben ik
erg blij.
In deze fase ga ik veel onderzoek doen in machine learning. Dat ga ik doen door het bekijken/lezen van verschillende bronnen, zoals een machine learning cursus op udemy, en kijken hoe ik deze informatie kan toepassen bij ons project (dit is erg belangrijk, want dit bepaalt immers voor een groot deel hoe ver we met unrest predictor kunnen komen).
Deze fase gaat over onderzoek doen in de aanpak van het developen. Hiervoor moeten we onderzoek doen in:
Deze fase houdt in afspraken maken met Diederick: hoe houden we contact en hoe houden we hem op de hoogte van de voortgang en vragen. Bijvoorbeeld:
In deze fase gaan we:
Deze fase is voor het opzetten van de technische omgeving. Hiermee wordt bedoeld:
Om de ML network te kunnen trainen heb ik data nodig. In het geval van dit project is dat news artikelen met wat er daarna is gebeurt in het bedrijf. Hier ga ik in ieder geval een week of 2 aan moeten zitten, aangezien het veel data moet gaan worden voor een zo accuraat mogelijk product.
Om de data daadwerkelijk te kunnen gebruiken moet het als eerst opgeschoond worden. Dit houdt in dat interpunctie en sommige woorden verwijderd moeten worden omdat het niet nodige informatie is voor de MLN.
In deze fase ga ik starten met het ontwikkelen van de MLN. Ik ga in deze fase de eerste versie maken van de MLN. Deze versie zou ongetwijfeld niet de beste zijn, maar het is een goed begin.
Met het begin dat ik in fase 9 heb opgezet wil ik verder werken om te verbeteren wat er te verbeteren valt. Dit kan betekenen dat ik verschillende instellingen van hoeveelheid hidden layers en hoeveelheid neuronen aanpas en kijk wat beter werkt.
Wanneer ik mijn MLN genoeg getest heb en het werkt goed is het klaar om aan Diederick te verkopen. Ik weet nog niet zeker of ik dit allemaal af ga krijgen voor het einde van deze school periode, maar ik ga mijn best doen!!!
"Het eindproduct wordt een webapplicatie dashboard. Via een overzicht kan je
alle bedrijven zien en of het onrustig is. Daarnaast wordt er met kleurcodes de
prioriteit van elk bedrijf aangegeven en weet je wanneer het beste moment is om contact
te gaan opnemen met de werknemers van het bedrijf. Daniël Gebben (mijn project genoot en
ex-klasgenoot) gaat zich focussen op dit
overzicht. Ik ga voornamelijk bezig met het onzichtbare gedeelte van de website.
De applicatie moet namelijk de onrust bij een bedrijf kunnen voorspellen. Dit gaat
mogelijk
gemaakt worden door een machine learning network. Een MLN (machine learning network) is
een soort programma dat heel goed verbanden kan leggen tussen data. Om zo'n MLN deze
verbanden te laten vinden moet je het programma trainen met veel testdata en veel
tijd. De MLN zal verbanden uit deze data kunnen halen en die dan toepassen op nieuwe
data dat je hem geeft.
Ik hoop dat ik een MLN kan trainen om uit Google Alerts te kunnen halen
of bijvoorbeeld een bedrijf failliet gaat of dat er fusie plaatsvindt. Met die data
kunnen we
dan aangeven hoeveel onrust er bij een bedrijf is. We hebben namelijk van Diederick
een tabel gekregen met hoeveel unrust bij zo'n gebeurtenis zou kunnen ontstaan.
Met deze tool is het dus mogelijk om in te spelen op de onrust bij bedrijven zodat je
kandidaten activeert die latent op zoek zijn."
Dit was een van de eerste beschrijvingen
van het product. Sindsdien is Unrest Predictor een veel grotere taak geworden dan het
eerst leek. Er waren een paar dingen waar ik geen rekening mee had gehouden.
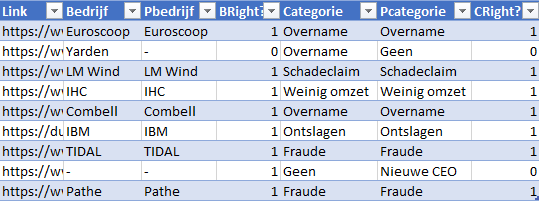
Ten eerste is de hoeveelheid MLNs verdubbeld. In plaats van 1 MLN die de categorie raadt
zijn het er nu 2. Want als je alleen een categorie hebt, heb je er niet zoveel
aan, je moet ook weten om welk bedrijf het gaat. Er is dus nog steeds een MLN die de
categorie raad maar nu ook een MLN die moet raden
over welk bedrijf het nieuwsbericht gaat. Ik ben tijdens
het maken van de dataset achter gekomen dat er niet veel nieuwsberichten waren waar
meerdere bedrijven het onderwerp waren. Vandaar om het product makkelijker te maken heb
ik ervoor gekozen uit een nieuwsbericht maar een bedrijf te halen.
Ten tweede had ik het maken van de dataset erg onderschat. Het duurder veel langer dan
ik dacht. Ik zat uiteindelijk 4 weken (ik dacht dat maar 2 weken zou kosten) vast aan
deze saaie, herhalende taak. Elke dag
nieuwsberichten opzoeken van een van de categorieën vervolgens alle nieuwsberichten
afgaan op zoek naar een nieuwsbericht die goed was. Na de eerste paar dagen was ik het
al zat. Maar ik zette door en heb uiteindelijk een mooie dataset bij elkaar kunnen
krijgen waar ik erg trots op ben!
Daarnaast hadden Diederick, Daniël en ik nog meer categorieën toegevoegd. Zoals wanneer
er onderzoek naar een bedrijf wordt gedaan, als een bedrijf schulden heeft en als er een
groep mensen onslagen word. Omdat er meer categorieën zijn bij gekomen was het maken van
de dataset en MLN lastiger geworden. Er moesten meer dataset entries bij wat weer meer
van mijn tijd nam en de MLN werd een stuk complexer om te trainen. De MLN raakte in het
begin erg in de war door de introductie van nieuwe categorieën maar na het door blijven
trainen kreeg hij die categorieën ook onder de knie.

Voor dit project had ik een aantal doelen. Deze doelen zijn te verdelen in project doelen en persoonlijke doelen. Mijn project doelen gaan voornamelijk over het eindproduct en de kwaliteit ervan. De persoonlijke doelen gaan meer over het (door)ontwikkelen van mijn skills.
Ik wil een werkend prototype machine learning network gemaakt hebben die uit google alerts kan halen of er een van de volgende gebeurtenissen plaats vind:
Dit is meetbaar door aan het eind van de minor het netwerk op die hierboven opgenoemde punten te testen. Bij het begin van deze minor stond er nog niks dus de vordering op dit vlak is alles dat ik nu af heb kunnen maken. Ik ben erg trots hoever ik ben gekomen hiermee. In het begin van deze minor dacht ik alles af te krijgen, wat jammer genoeg niet is gebeurt. Maar toen ik eenmaal bezig was merkte ik pas hoeveel werk dit project zou worden en waardeer ik hoever ik gekomen ben meer. Uiteraard ga ik na de minor verder met het product om een goed werkende MLN aan Daniël en Diederick te leveren.
Ik wil niet alleen een werkend product maken maar ook een product waar
Daniël, Diederick en ik
trots op kunnen zijn. Dit ga ik meten door feedback van Diederick en Daniël te vragen
daarnaast wil ik ook zelf aangeven hoe tevreden ik ben. Ik wil deze meting elke sprint
gaan meten.
Uiteindelijk heb ik dit niet elke sprint gemeten. Dat komt omdat in de eerste periode,
tot en met de status update, dit niet gemeet kon worden. Er was namelijk geen product
voor Diederick om naar te kijken. Ik heb wel toen Daniël en ik Diederick de eerste
versie van het product lieten zien, Diederick gevraagd naar zijn tevredenheid. Diederick
was erg tevreden met de snelheid van het developen en de kwaliteit van het product. Hij
vond het geweldig om het product dat hij bedacht had uitgewerkt voor hem te zien. Daniël
zei dat hij erg blij was met wat ik opgeleverd had en beschreef het samenwerken met mij
als prettig en soepel.
Voordat je een machine learning network kan maken moet je het natuurlijk eerst verzinnen. In het Plan van Aanpak schreef ik dit:
"Ik zou graag een machine learning network kunnen ontwerpen. Op dit moment kan ik het nog totaal niet. Maar ik wil het gaan leren door diverse bronnen te bekijken/lezen. Ik heb nu al een cursus op het oog van Udemy die ik wil gaan uitproberen. Dit is meetbaar door een machine learning network te ontwerpen en vervolgens te bouwen. Als de gebouwde netwerk doet wat je had verwacht klopt het. Ik wil dit doel gaan testen bij de statusupdate en de eindverantwoording."
In mijn Status Update had ik om dit doel te testen een MLN ontworpen die kan raden wat
je aan het tekenen bent. Dat was een groots succes aangezien het de eerste niet
begeleide ontwerp was van een MLN. Ik was super blij met het resultaat!
Om dit doel te testen voor mijn Eindverantwoording had ik de MLN's voor Unrest Predictor
ontworpen. Dit ontwerp was simpeler aangezien ik een ander predictie model (Multinomial
Naive Bayes classifier) heb gebruikt. Voor dit model hoef ik niet aan te geven hoeveel
neuronen ik wil gebruiken wat het ontwerpen een stuk minder ingewikkeld maakt. Het enige
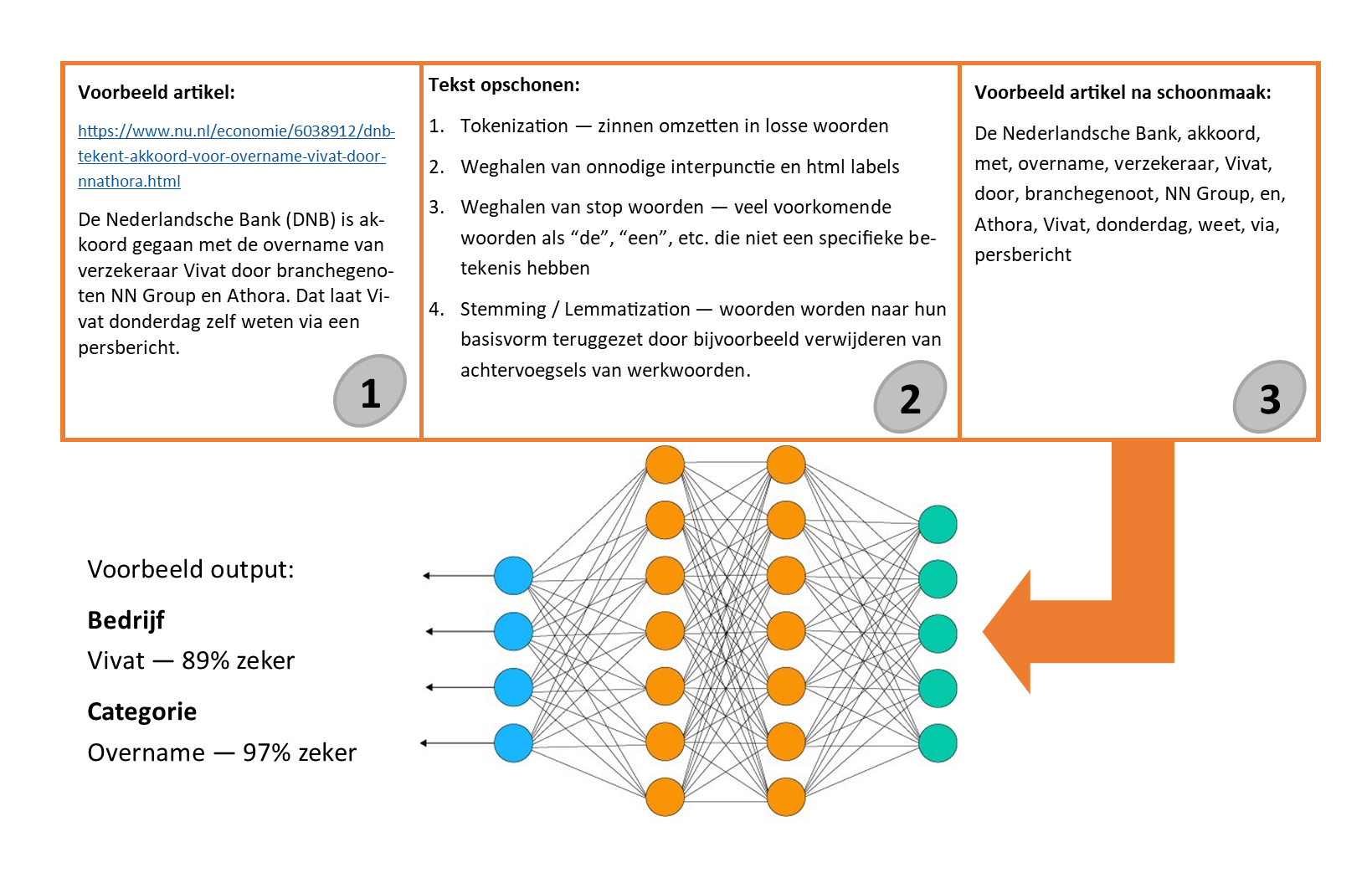
wat ik moest ontwerpen voor de twee MLN's was hoe de data eruit kwam te zien. De input
bestaat uit de artikelen zonder reclames, interpunctie en stopwoorden. Vervolgens heb ik
de dataset in twee delen gesplitst, een
traindataset en een testdataset. De traindataset (65% van de data) is om de MLN's te
trainen en de testdataset (35% van de data) is om na het trainen te testen hoe accuraat
de MLN's zijn. Dit ontwerp had ik gebruikt voor mijn volgende doel.
Na het ontwerpen van een machine learning network komt het bouwen van het netwerk. In mijn Plan van Aanpak schreef ik dit:
"Ik zou graag een machine learning network kunnen bouwen. Op dit moment kan ik er nog niks van. Ik wil ook dit gaan leren van verschillende bronnen waaronder de Udemy cursus. Dit doel is meetbaar door het daadwerkelijk maken van een machine learning network die ik van tevoren bedacht heb. Ik wil dit doel gaan testen bij de statusupdate. Dit doel is mijn vijfde competentie."
In mijn Status Update had ik om dit doel te testen een MLN gemaakt die kan raden wat je
aan het tekenen bent. Voor mijn andere persoonlijke doel had ik deze MLN eerst
ontworpen. Het process verliep soepel ik had de MLN in 2 weken kunnen maken en
finetunen.
Om dit doel te testen voor mijn Eindeverantwoording had ik de MLN's voor Unrest
Predictor gemaakt. Het ontwerp werkte goed maar er waren twee paar dingen die iets
anders
moesten. Ten eerste moesten de worden naar hen basisvorm veranderd, bijvoorbeeld door
maar een soort vervoeging van werkwoorden te gebruiken. Dit implementeren had de MLN's
hun accuratiepercentage omhoog gehaald met ongeveer 5%. Daarnaast kwam ik erachter dat
het beter werkte als ik in plaats van zinnen in de MLN te stoppen, losse woorden te
gebruiken. Wat de percentage deed stijgen met 2%.
Het bouw process verliep goed. In wat korter dan twee weken had ik een goede eerste
prototype neergezet waar Daniel, Diederick en ik allemaal blij mee zijn. Ik kwam maar
tegen twee kleine probleempjes die ik hierboven had beschreven. Maar die oplossingen
waren makkelijk online te vinden. Voor de rest had ik veel herhaald wat ik met de
opdracht van mijn vriendin ook moest doen. Vandaar liep het proces zo soepel.
Deze minor zou niet zo goed gelopen zijn als ik niet de hulp had van een aantal mensen. Deze mensen zijn:
Ik zou graag deze mensen hartelijk willen bedanken voor alle hulp die ik heb gekregen, de leuke en zware tijden die we hebben meegemaakt en voor alles wat ik geleerd hebt.